How AI-Native Engineers Catch What AI Gets It Wrong

Have you ever watched a junior developer ship code that looked perfect on the surface, only to discover three weeks later that it had been silently breaking things the whole time?
That is what working with AI tools feels like for most engineering teams right now. The output looks clean. The syntax is correct. The logic appears sound. And then something breaks in production that should never have broken, and the post-mortem reveals that nobody actually questioned whether the AI got it right.
This is the conversation the engineering industry needs to have honestly. Not about whether AI tools are useful, they clearly are, but about the gap between teams that use AI and teams that use it well. At TeamScaler, we work with engineering leaders across the US and Europe, and the pattern we keep seeing is always the same. The teams that get the most out of AI-native development are not the ones with the most tools. They are the ones with the most experienced engineers holding those tools.
The incident nobody talked about loudly enough
In early 2025, a widely cited case emerged from the open-source community. A GitHub Copilot-authored commit replaced a value with a named constant but never actually defined that constant anywhere in the codebase. The code passed review. It was merged. It sat in the repository for over three weeks before a maintainer caught it during an unrelated debugging session. The finding was documented in a large-scale empirical study of AI-generated code published on arXiv, which analyzed real-world repositories and found that developers consistently tend to over-trust and accept AI suggestions without thorough review.
This was not an edge case. It was a pattern.
The numbers behind the pattern

A peer-reviewed study from the University of Luxembourg, published in Frontiers in Data Science, conducted a systematic review of AI code generation across multiple models and found that AI code generation offers no guarantee of security, with recent research consistently showing that AI models produce software with vulnerabilities. A separate large-scale analysis of 7,703 files attributed to major AI tools across public GitHub repositories, published on arXiv in October 2025, identified 4,241 vulnerability instances across 77 distinct weakness types. Python consistently showed the highest vulnerability rates, ranging from 16 to 18 percent, with JavaScript not far behind.
The research that cuts deepest, however, comes from a formal verification study published in April 2026 that examined 3,500 code artifacts generated by seven widely deployed AI models across 500 security-critical prompts. The finding was stark: AI-generated code deployed in security-sensitive environments requires rigorous human validation, not because the code looks wrong but precisely because it so often looks right.
This is the crux of the problem. The danger is not the obviously broken output. It is the confidently produced, syntactically clean, logically plausible code that contains a subtle vulnerability nobody checked for because nobody thought to question it.
Why experience is the variable that changes everything
Here is where the hiring conversation gets interesting for engineering leaders.
A Fastly survey of 791 developers published in July 2025 found that senior developers with ten or more years of experience ship nearly two and a half times more AI-generated code than junior developers. Not because they are less careful. Because they are more capable of catching what needs to be caught before it ships. They recognize when code looks right but is not. They know which patterns to interrogate. They understand which edge cases the AI has never been trained on because those cases live in production environments, not in publicly available training data.
The same Qodo State of AI Code Quality 2025 research found that while senior engineers see the largest quality gains from working with AI tools, they also report the lowest confidence in shipping AI-generated code without validation. That apparent contradiction is actually the most important finding in the study. The engineers who know the most are the ones who trust the output the least. And that distrust is exactly what makes their output safer.
A junior developer sees AI as a teacher. An experienced engineer sees it as a junior colleague whose work needs checking. That shift in perspective is not something you can train in a week. It is built over years of debugging production failures, shipping under pressure, and understanding the specific ways that things go wrong in real environments.
What AI-native engineers actually do differently
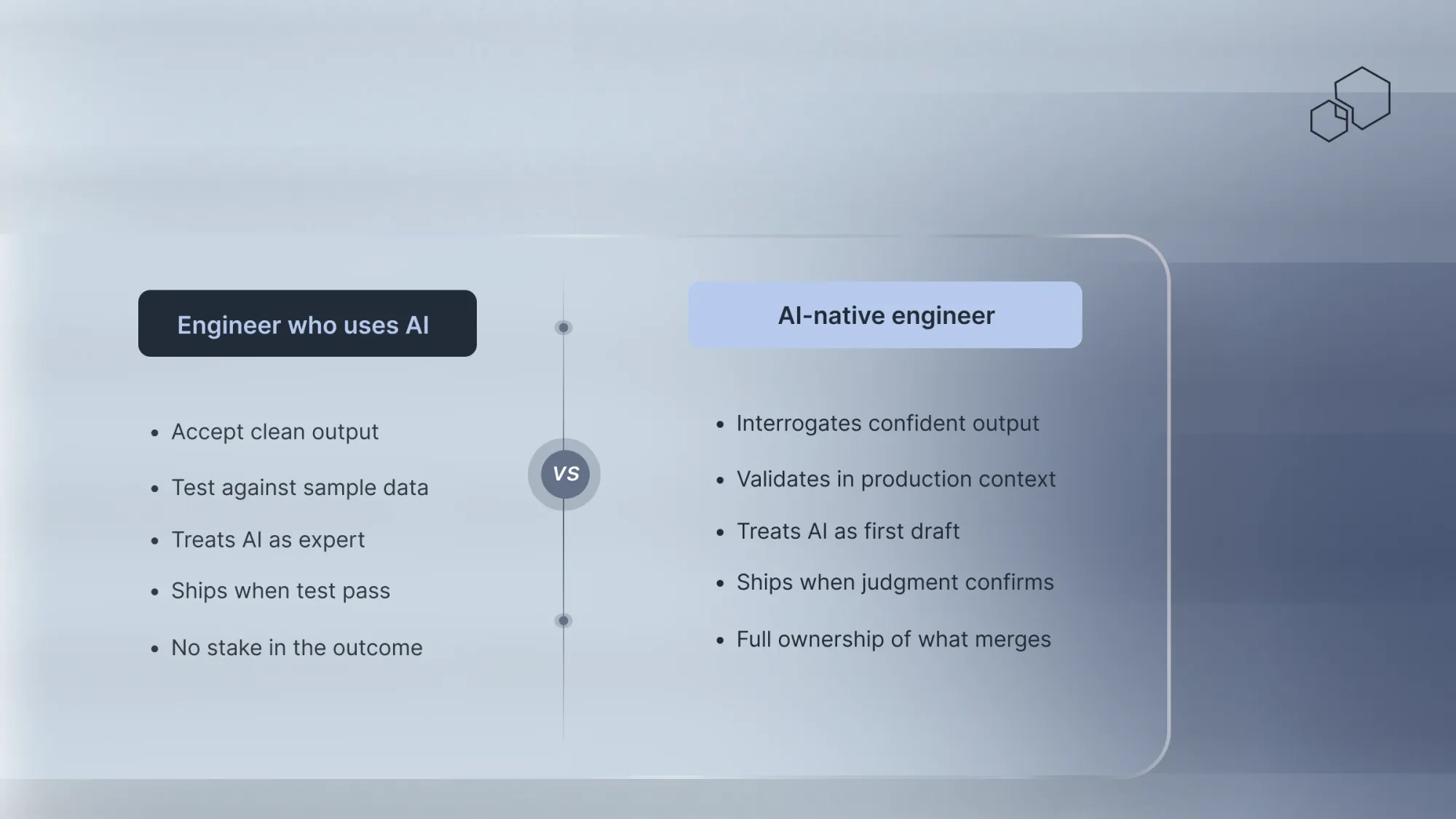
The phrase “AI-native” gets used loosely. At TeamScaler, we use it to describe something specific. Engineers for whom working with AI is not a new skill but a default mode, and who bring the experience and judgment to validate that work before it reaches production.
The difference shows up in three consistent practices that separate engineers who use AI well from those who use it dangerously.
First, they validate in context. Not against a generic test suite but against the specific environment the code will run in. They ask whether the AI understands the version constraints, the legacy dependencies, the production configuration that does not exist in any public repository.
Second, they interrogate the confident outputs hardest. A good AI-native engineer is most suspicious when the AI is most certain. Confidence in AI output is not a signal to ship. It is a signal to look more carefully.
Third, they treat every AI output as a first draft written by someone who has never seen the production environment. Because that is exactly what it is.
What this means if you are leading an engineering team
If you are evaluating AI tool adoption for your engineering team, the research points to one conclusion that most vendor conversations will never give you. The productivity gains from AI development are real. But they are not evenly distributed. They accrue to the teams with experienced engineers who have the judgment to know when not to trust the output.
A randomised controlled trial conducted by METR in 2025, widely regarded as the most methodologically rigorous study of AI developer productivity to date, found that experienced developers using AI tools completed tasks 19 percent slower while believing they were 20 percent faster. The perception gap of 39 points is not a curiosity. It is a warning. Teams making strategic decisions about AI adoption based on how fast their engineers feel are making those decisions on the wrong data.
The real question is not which AI tools your team should use. It is whether the engineers using those tools have the experience and the accountability to catch what the tools get wrong. As the old saying goes, a tool is only as good as the hand that holds it. In AI-native development, that hand needs to belong to someone who has seen enough production failures to know exactly where to look.
TeamScaler engineers are placed specifically for this combination of AI fluency and production experience. Every engineer we place is in the top 3 percent of candidates assessed, evaluated not just for technical skill but for the ownership mindset that makes the difference between AI-generated code that ships safely and AI-generated code that breaks quietly for three weeks before anyone notices.
AI is not going to slow down. The teams that figure out how to use it with genuine skill and genuine accountability are the ones that will pull ahead. Everyone else will spend their time fixing what the tools got confident about.
The engineers who make AI-native development actually work are not the ones who use AI the most. They are the ones who know exactly when not to.
Ready to build a team that ships faster and breaks less? Let’s talk.