How a TeamScaler Engineer Closed an Eight-Month Security Gap on Day One

When did someone last look at your hosting infrastructure like they’d never seen it before?
This is a story about what was quietly sitting in one hosting company's environment, and what happened the moment a fresh pair of experienced eyes walked in.
The environment before the engineer arrived
The client was a mid-sized web hosting company serving several hundred US businesses across shared hosting, VPS, and dedicated server packages. Their Linux and cPanel stack was managed by a tight internal team backed by a third-party support arrangement covering overnight tickets.
On paper, everything looked fine. Tickets closed. SLAs met. No client complaints.
But there’s a difference between knowing an environment and seeing it clearly. When you’ve provisioned the same servers dozens of times and managed the same infrastructure for years, you develop a fluency that's great for speed and dangerous for security. You stop questioning configurations set by someone who left eighteen months ago. You stop noticing what's always been there.
The team wasn’t negligent. They were familiar. In hosting infrastructure, unchallenged familiarity is indistinguishable from a gap.
What the engineer noticed before lunch
The TeamScaler infrastructure engineer joined on a Monday morning. Standard environment walkthrough. First few hours, nothing unusual.
Then something stood out.
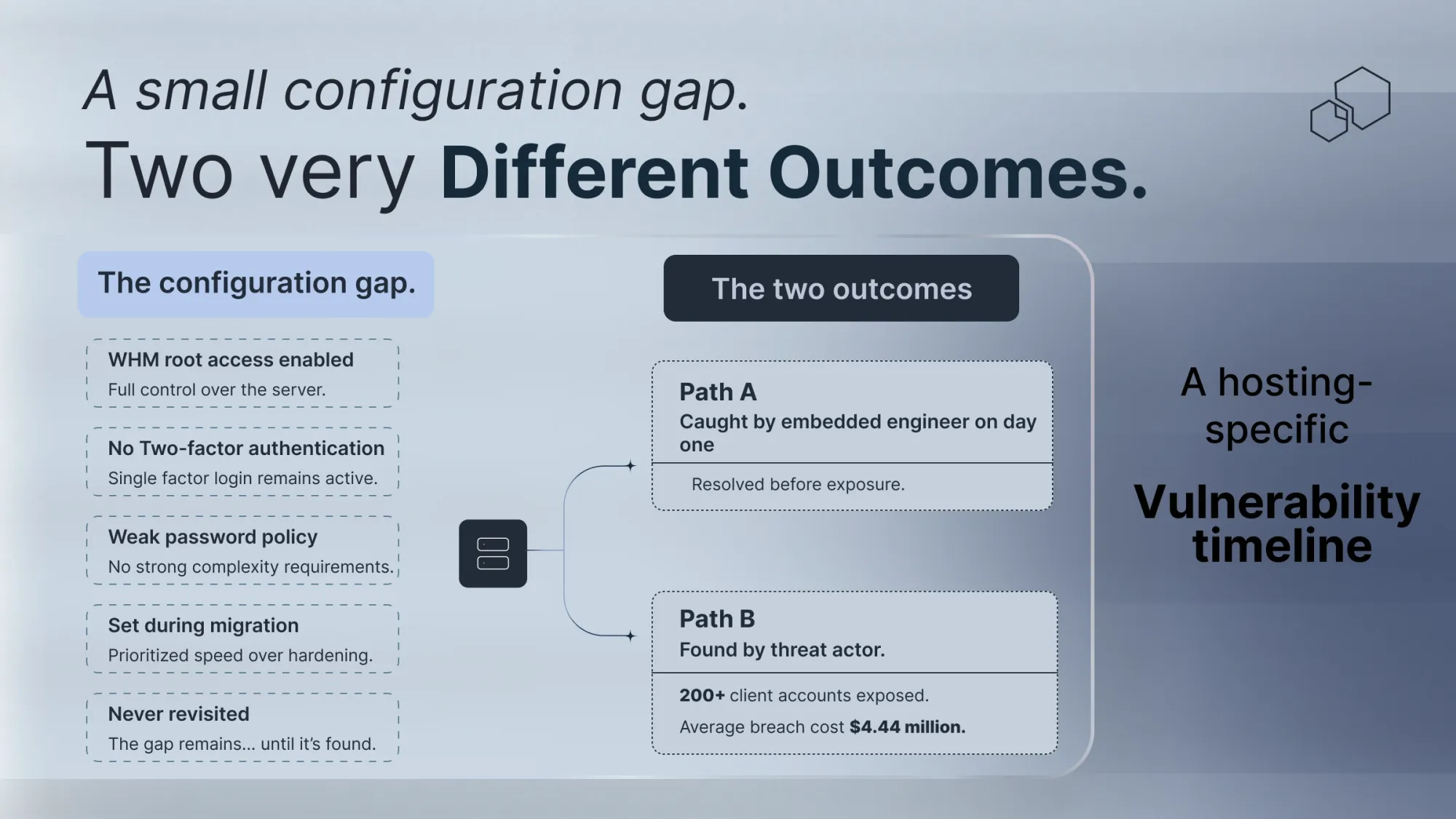
A WHM root access login, active, no two-factor authentication. It had been configured during a server migration eight months earlier, flagged internally as temporary, and never revisited. The server wasn’t obscure. It was core shared hosting infrastructure, carrying accounts for over two hundred business clients.
An experienced engineer doesn’t need a security scan to catch this. They recognize it because they’ve seen where it leads. They know what a threat actor does when they find an authenticated management interface with weak access controls. They know how lateral movement works through a cPanel environment. They know what the client conversation sounds like after the fact.
The engineer flagged it before lunch.
What the exposure actually looked like
Two hundred business clients. One server. One management interface with root access, no two-factor authentication, and a password policy untouched since the migration.
If the wrong person had found it first, the damage wouldn't have stopped at the hosting company. It would have reached every client on that server, their files, their customer records, their business continuity.
This is what makes hosting infrastructure uniquely dangerous. A single misconfiguration doesn't just expose you. It exposes everyone who trusted you with their infrastructure.
The Verizon 2025 Data Breach Investigations Report, which analyzed over 22,000 incidents, found that misconfigurations account for more than 25% of all breaches, particularly in cloud and managed hosting environments. Third-party involvement in breaches doubled year over year, now accounting for 30% of all incidents. For a hosting company, that's not a statistic. It’s an existential risk.
The IBM Cost of Data Breach Report 2025 puts the global average breach cost at $4.44 million. US organizations average $10.22 million per incident. For a mid-sized hosting company, that's not just money. It's clients, contracts, and years of reputation.
What happens when nobody catches it first
In early 2023, Lumen Technologies disclosed a ransomware attack targeting a segmented hosting service, causing service disruptions for enterprise clients and significant remediation effort. The pattern was familiar: reactive support coverage, engineers responding to what was reported rather than watching for what hadn't been reported yet.
A similar story unfolded with Tietoevry in early 2024, when the Akira ransomware group compromised their infrastructure and cascaded through dozens of client organizations, including government authorities and universities. The initial compromise point had never been identified before it was exploited.
Neither attack required sophistication. Both required a gap that an embedded engineer would have been positioned to close.

How it was resolved without a single client noticing
The engineer documented the finding, briefed the operations director clearly and without alarm, and proposed a remediation window that wouldn't touch live client services.
Two-factor authentication enabled. Root access restricted to verified IPs. Password policy reviewed and updated. An audit of similar configurations across the rest of the infrastructure scheduled for the following week.
Done before the end of the first week. No client disruption. No breach. An eight-month gap, closed because someone looked at the environment for the first time without assuming everything was fine.
That's what embedded managed cloud support engineering looks like at TeamScaler. Not engineers working a ticket queue. Engineers who own the environment from the moment they arrive.
Why your current support model might be missing the same thing
The Cloud Security Alliance Top Threats to Cloud Computing 2025 identifies IAM misconfigurations as a primary attack vector, allowing threat actors to escalate privileges and move laterally through infrastructure. In shared hosting environments, lateral movement isn't just a security concept. It's the mechanism by which one client's problem becomes every client's problem.
Ticket-based support responds to what clients report. Embedded engineering catches what clients will never think to report, because they don't know it exists.
That gap is exactly what had been sitting in this client's WHM configuration for eight months.
Three questions every hosting operations director should ask today
One: Does anyone on your current support team have a structured process for reviewing configurations set during migrations that were never formally revisited? In an organically grown hosting environment, these accumulate silently, not on any incident report, not in any ticket.
Two: If a client’s server was compromised through a misconfiguration tonight, how long would it take your team to identify the source, contain the damage, and notify affected clients? IBM’s 2025 research puts the average at 241 days. For a hosting company, that's not just a cost. It's a client retention crisis.
Three: When your support engineers look at your infrastructure, are they seeing it, or looking at something they’ve learned to assume is fine?
That last question is the most useful security assessment you can run. It costs nothing except the willingness to ask it honestly.
What this means
The engineer in this story didn’t do anything extraordinary. They looked at a new environment with experienced eyes and noticed what eight months of familiarity had made invisible.
That's not a special gift. It's what happens when the right engineer is embedded in your operations.
The configuration caught on day one is the one that doesn't become the worst week your hosting company has ever had.
Is there a configuration in your hosting infrastructure that fresh eyes would find today? Let’s talk today and find out what the right managed cloud support engineers would see.
